


:quality(85)//cloudfront-us-east-1.images.arcpublishing.com/infobae/SSR7LOYJ4ZD6LDFDG6DHQZRD5Q.JPG "Impressive AI software that recreates faces from sound")
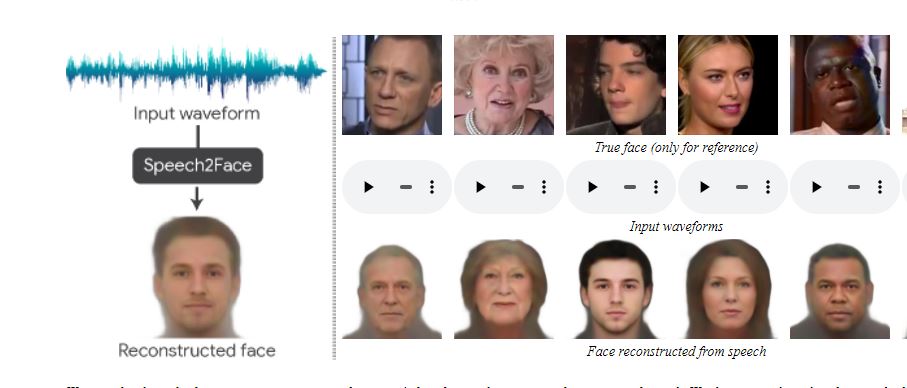
Technology continues to grow by leaps and bounds, drawing on different areas to explore new capabilities and features. One of them is strength. “Reconstruct” a person’s face with a portion of the voice.
the study Speech 2 face It was presented in 2019 at the Patterns of Seeing and Recognition conference that showed that Artificial Intelligence (AI) can do it Decode a person’s shape through short audio clips.
The document explains that the goal of researchers Tae Hyun Un, Tali Dikle, Changel Kim, Inbar Mosseri, William T. Freeman, and Michael Rubinstein of the MIT Science and Research Program is not to reconstruct people’s faces symmetrically but to create an image with the physical properties associated with the analyzed sound.
To achieve this they used Deep neural network design and training I analyzed millions of videos taken from YouTube where people are talking. During training learn the model Connecting sounds to facesallowing you to produce Pictures with physical characteristics similar to loudspeakersincluding Age, gender and race.

Training was carried out under supervision and using Matching faces and voices From online videos, without the need to model the detailed physical features of the face.
“The reconstructions, obtained directly from audio, reveal the interrelationships between faces and sounds. We quantify, quantify, and in what way, our Speech2Face reconstructions from audio resemble real images of the faces of the speakers.”
They show that because this study could have sensitive aspects due to race, as well as privacy, no specific physical aspects were added to the facial reconstitution and they confirm this, like any other aspects. . system machine learning, This gets better over time, because with each use it increases its knowledge library.
Although the evidence shows it Speech2Face has a large number of matches between faces and voicesalso has some drawbacks, in which race, age, or gender do not match the audio sample used.
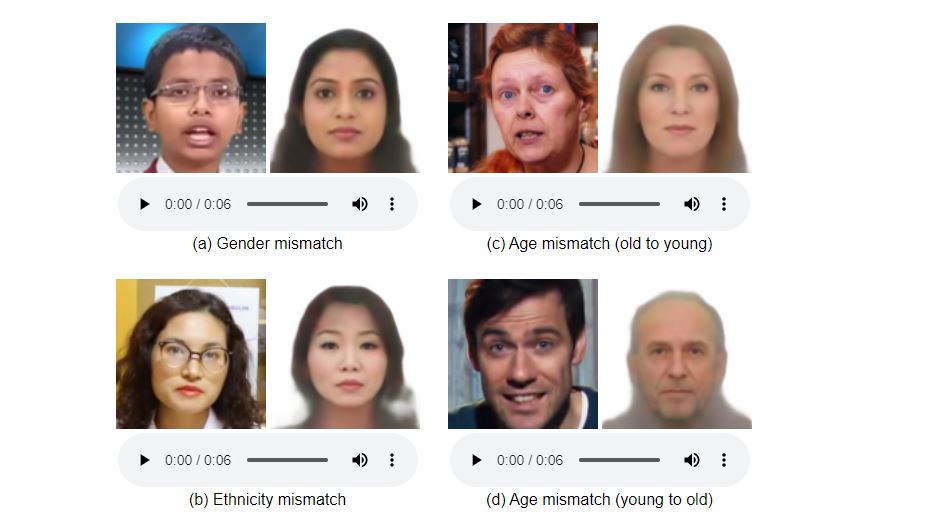
The form is designed to present Statistical correlations between facial features with voice. It must be remembered that AI learned from YouTube videos, which do not represent a real sample of the world’s population, for example, in some languages there are inconsistencies with the training data.
In this sense, the study itself recommends, at the end of its findings, that those who decide to explore and update the system take into account a broader sample of people and voices so that it is done in this way machine learning when Wider repertoire of face matching and entertainment.
The program was also able to recreate the sound in the cartoons, which also bear an amazing resemblance to the voices in the analyzed phonemes.
Since this technology can also be used for malicious purposes, re-creating the face only preserves the closest thing to the person and does not give full faces, as this can be a problem for people’s privacy. However, he was surprised by what the technology could do with audio samples.
Read on:

“Problem solver. Proud twitter specialist. Travel aficionado. Introvert. Coffee trailblazer. Professional zombie ninja. Extreme gamer.”
More Stories
With a surprise in the case: a strange cell phone from Nokia was introduced
PlayStation Stars: what it is, how it works and what it offers to its users | Sony | video games | tdex | revtli | the answers
t3n – Digital Pioneers | digital business magazine